https://www.youtube.com/watch?v=1j0W_lu55nc
최근 스테이블 디퓨전(Stable Diffusion)과 같은 이미지 생성 AI가 보여주는 퍼포먼스는 경이로움 그 자체입니다. 아무 의미 없는 노이즈 섞인 화면에서 서서히 형체가 잡히더니, 마치 사진작가가 찍은 듯한 고화질 이미지가 나타나는 과정은 마치 마법처럼 느껴지죠. 하지만 과학의 눈으로 보면 이는 우주의 근본 원리인 '엔트로피 증가의 법칙'을 정면으로 거스르는 거대한 역전극입니다.
이 모든 열풍의 시초에는 2020년 발표된 DDPM(Denoising Diffusion Probabilistic Models) 논문이 자리 잡고 있습니다. 2015년 처음 제안된 '확산(Diffusion)'이라는 초기 개념이 어떻게 실질적인 생성 AI의 표준으로 자리 잡게 되었는지, 그 결정적인 4가지 순간을 짚어보겠습니다.
--------------------------------------------------------------------------------
1. 한 번에 완성하는 시대는 갔다: '이터러티브(Iterative)'의 승리
과거의 딥러닝 모델들은 입력값을 넣으면 한 번에 결과물을 출력하는 '엔드 투 엔드(End-to-End)' 방식이 주를 이뤘습니다. 하지만 DDPM은 한 번에 완벽한 이미지를 그려내겠다는 욕심을 버리고, 수천 번의 미세한 수정을 거쳐 품질을 높여가는 '반복의 미학'을 선택했습니다.
이는 옵티컬 플로우(Optical Flow) 분야의 혁신을 일으켰던 RAFT 모델의 철학과 맞닿아 있습니다. RAFT가 반복적인 구조를 통해 결과물을 점진적으로 개선했듯, 디퓨전 모델 역시 노이즈에서 시작해 1,000단계에 이르는 반복을 거치며 이미지를 정교화합니다. 특히 DDPM은 최종 결과물에만 집중하는 것이 아니라, 모든 중간 과정마다 적절한 가이드(Loss)를 제공하여 모델이 길을 잃지 않도록 설계되었습니다.
"요즘은 특히나 테스트 타임에서 뭔가 이것저것 많이 하려고 하는 어떤 접근들이 항상 성능도 좋고 퀄리티도 좋고 이런 결과들이 많이 보여주는 거 같아요."
이처럼 '추론 시점(Test-time)'에 공을 들이는 전략은 생성 모델의 패러다임을 '단판 승부'에서 '점진적 완성'으로 완전히 바꾸어 놓았습니다.
2. 인간의 직관을 이식하다: 학습을 포기하고 얻은 효율성
흔히 딥러닝은 모든 것을 데이터로부터 스스로 학습하는 것이 미덕이라고 여겨집니다. 하지만 DDPM은 오히려 모델의 자율성을 의도적으로 제한하는 '인덕티브 바이어스(Inductive Bias)'를 투입해 실용성을 극대화했습니다.
기존 디퓨전 모델은 노이즈를 섞는 강도(\beta_t)나 불확실성(Variance)까지 모델이 직접 학습하게 하려 했습니다. 하지만 DDPM은 과감하게 이를 고정(Fixed)했습니다. 구체적으로 \beta_t 값을 10^{-4}에서 0.02까지 1,000단계에 걸쳐 리니어(Linear)하게 증가하도록 사람이 직접 스케줄링한 것입니다.
이 결정은 매우 영리한 비평적 선택이었습니다. 모델에게 모든 자유도를 주어 학습의 난이도를 높이는 대신, 인간의 사전 지식을 설계에 반영하여 학습의 안정성을 확보한 것입니다. "학습 가능한 부분을 없애고 사람이 설계한 부분으로 대체했다"는 이 역설적인 선택이, 실험실에 머물던 디퓨전 모델을 실용의 영역으로 끌어올린 결정적 한 수가 되었습니다.
3. '무엇'이 아닌 '얼마나'를 예측하기: 레지듀얼(Residual)의 마법
DDPM이 문제를 해결하는 방식은 기술적으로 매우 영리합니다. 모델에게 "이 노이즈 섞인 사진의 원본(Mean, \mu_\theta)이 뭐야?"라고 묻는 대신, 여기에 추가된 노이즈(\epsilon)가 정확히 얼마나 섞여 있어?라고 묻는 방식으로 설계를 바꾼 것입니다.
이는 슈퍼 레졸루션(VDSAR) 기술에서 이미 알고 있는 정보를 최대한 활용하고 '차이점(Residual)'만 찾아내는 방식과 유사합니다. 사실 노이즈가 섞인 이미지(x_t)는 이미 원본의 정보(\mu_\theta)를 상당 부분 포함하고 있습니다. 따라서 원본 전체를 처음부터 다시 예측하는 것은 모델 용량의 낭비에 가깝습니다. 대신 이미 알고 있는 정보에서 '추가된 노이즈'라는 차이점만 찾아내도록 유도함으로써, 모델은 훨씬 더 쉽고 정교하게 고화질 이미지를 복원해낼 수 있게 되었습니다.
4. 생성 모델의 삼각관계: 품질, 다양성, 그리고 속도
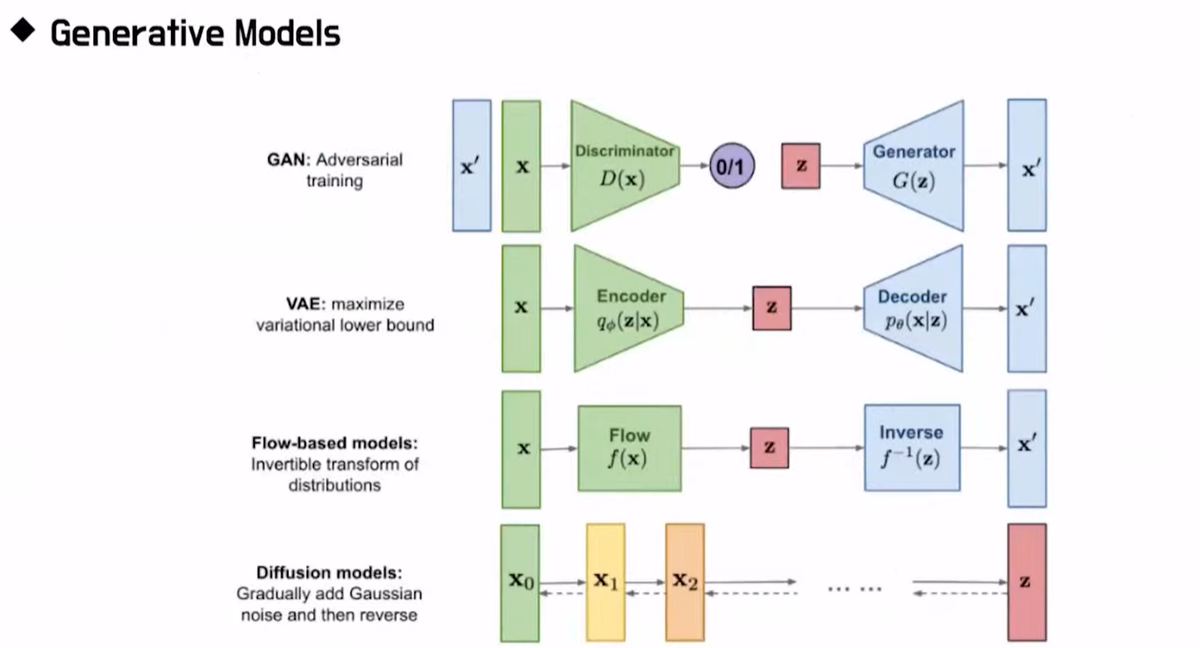
생성 모델의 세계에는 품질, 다양성, 속도라는 세 마리 토끼를 잡기 위한 치열한 경쟁이 존재합니다. DDPM은 기존의 GAN, VAE, Normalizing Flow와 비교했을 때 독보적인 위치를 점합니다. 특히 디퓨전 모델은 VAE나 Flow 모델과 달리 인코더(Encoder)가 고정(Fixed)되어 있다는 구조적 특징을 가집니다.
- 장점: 압도적인 샘플 퀄리티와 다양성
- 품질: FID 스코어 등 정량적 지표에서 GAN을 압도할 만큼 정교한 이미지를 생성합니다.
- 다양성: GAN의 고질병인 '모드 컬랩스(Mode Collapse, 비슷한 이미지만 반복 생성하는 현상)' 없이 데이터셋의 넓은 분포를 충실히 표현합니다.
- 단점: 느린 샘플링 속도
- 수천 번의 반복(Iteration)을 거쳐야 하므로 한 번에 결과를 내는 모델들에 비해 상대적으로 속도가 느립니다.
비록 속도라는 숙제가 남았지만, DDPM은 품질과 다양성이라는 생성 모델의 본질적인 가치를 완벽하게 증명하며 예술적 생성의 시대를 열었습니다.
'멀티모달' 카테고리의 다른 글
| LoRA: Low-Rank Adaptation (0) | 2026.04.06 |
|---|---|
| VAE(Variational Auto-Encoder) (0) | 2026.04.06 |
| Attention (0) | 2026.04.06 |
| Stable Diffusion (0) | 2026.04.06 |
| ComfyUI+n8n연동 (0) | 2026.04.05 |