우리가 일상에서 사용하는 언어는 사실 고도의 '눈치 게임'입니다. 예를 들어 'mole'이라는 단어를 들었을 때, 여러분은 무엇을 떠올리시나요? 누군가는 땅속의 '두더지'를, 누군가는 화학 시간의 '분자 단위'를, 또 누군가는 피부에 난 '점'을 떠올릴 겁니다. 우리는 주변 단어들을 통해 이 모호함을 순식간에 해결하지만, 컴퓨터에게 이 '문맥(Context)'을 가르치는 것은 오랜 난제였습니다.
2017년 등장한 '트랜스포머(Transformer)' 모델은 이 문제를 혁신적으로 해결하며 현대 AI의 심장이 되었습니다. 그 비결은 바로 어텐션(Attention) 메커니즘에 있습니다.
2. 고정된 의미는 없다: 임베딩 공간 속의 '이동'
AI가 처음 단어를 받아들이면, 이를 고차원 공간상의 점인 '임베딩(Embedding) 벡터'로 변환합니다. 초기 상태의 임베딩은 단어 본연의 사전적 의미만을 담고 있습니다. 하지만 어텐션 블록을 거치면서 이 점들은 문맥에 따라 공간 속에서 역동적으로 움직이기 시작합니다.
예를 들어 '타워(Tower)'라는 단어의 벡터가 있다고 해봅시다. 평소에는 그저 '높은 건물'을 향해 있던 이 벡터는, 앞에 '에펠(Eiffel)'이라는 단어가 나타나면 '파리', '프랑스', '철골 구조'라는 의미가 담긴 방향으로 급격히 이동합니다. 반대로 '미니어처(Miniature)'가 붙는다면 '거대함'이라는 속성에서 멀어지는 방향으로 수정되죠.
"이 단계에서 문맥을 통해 실제 저 몰(mole)이라는 방향을 실제 의미로 어디로 얼마나 움직여야 되는지를 모델이 알아간다고 생각하시면 됩니다. 문맥상 두더지라면 두더지 방향으로, 화학 분자 단위라면 그 방향으로 움직이게 되는 거죠."
결국 어텐션은 고정된 단어의 의미를 문맥에 맞게 실시간으로 재구성하는 '공간의 연금술'인 셈입니다.
3. 어텐션의 삼총사: 쿼리(Query), 키(Key), 밸류(Value)
이 마법 같은 이동을 가능하게 하는 핵심 장치가 바로 Q, K, V라는 세 가지 행렬입니다.
- Query(질문): "내가 지금 이 문맥을 이해하기 위해 어떤 정보가 필요하지?" (예: 나를 수식하는 형용사는 어디 있어?)
- Key(특징): "내가 가진 정보는 이런 성격이야." (예: 나는 '파란색'과 '보송보송함'을 설명하는 형용사야.)
- Value(내용): "필요하다면 이 정보를 줄게." (실제 가중치가 반영된 구체적인 정보)
여기서 흥미로운 점은 **내적(Dot Product)**의 활용입니다. 수학적으로 두 벡터의 방향이 비슷할수록 내적 값은 커집니다. 즉, 쿼리가 던진 질문과 키가 가진 특징이 공간상에서 같은 방향을 가리킬 때, AI는 "이 단어들이 서로 밀접한 관련이 있구나!"라고 판단합니다. 이 점수를 소프트맥스(Softmax) 함수에 통과시키면 합이 1인 확률 분포가 되어, 어떤 단어에 얼마나 집중(Attention)할지 결정하는 가중치가 됩니다.
여기서 Value(밸류)는 단순히 단어를 교체하는 것이 아니라, 원래 임베딩에 더해질 '수정 사항(Delta E)' 역할을 합니다. 밸류 정보는 효율성을 위해 작은 공간으로 압축되었다가(Value-down), 다시 원래의 고차원 임베딩 크기로 확장(Value-up/Output Projection)되며 더해집니다. 결과적으로 '생물'이라는 벡터에 '파란색'과 '보송보송한'이라는 밸류가 더해져, '파랗고 보송보송한 생물'이라는 더 구체적이고 풍부한 벡터로 진화하게 됩니다.
4. 미래를 보지 마세요: 마스킹(Masking)의 전략적 중요성
GPT와 같은 생성형 AI는 다음에 올 단어를 예측하며 학습합니다. 그런데 만약 학습 과정에서 모델이 뒤에 올 정답을 미리 슬쩍 볼 수 있다면 어떻게 될까요? 공부는 안 하고 답지만 베끼는 학생처럼 제대로 된 지능을 갖추지 못할 것입니다.
이를 방지하는 기술이 바로 마스킹(Masking)입니다. 문장 전체를 한 번에 입력하여 병렬로 학습시키되, 특정 단어가 자기보다 뒤에 나오는 단어의 정보를 결코 참조할 수 없도록 차단하는 '컨닝 방지 장치'죠. 소프트맥스를 적용하기 전, 미래 단어들과의 관련성 점수를 음의 무한대로 설정해 버리면 가중치가 0이 되어 정보가 흐르지 않게 됩니다. 이 전략 덕분에 AI는 과거의 단어들만 가지고 미래를 추론하는 법을 효율적으로 배울 수 있습니다.
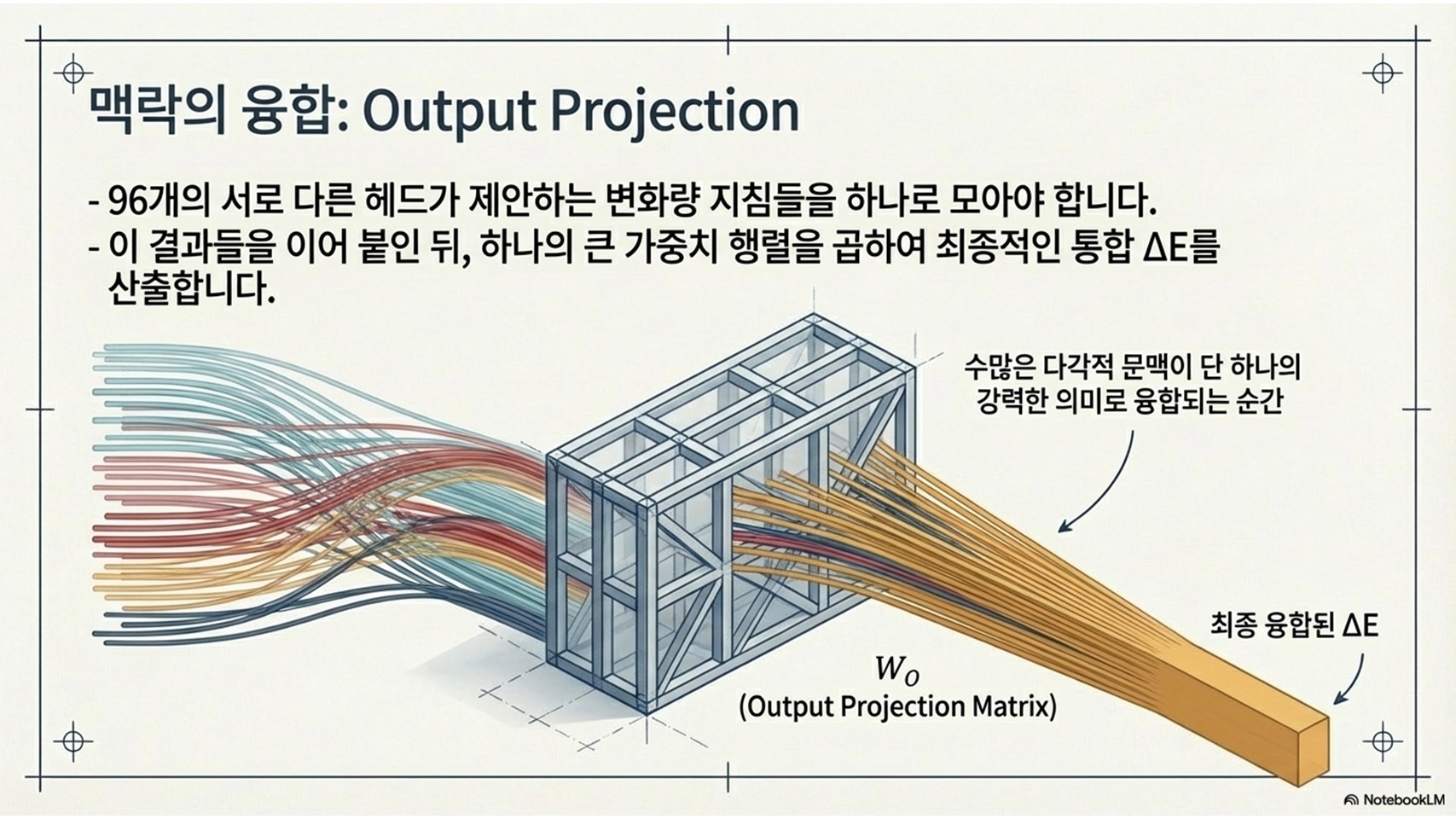
5. 96개의 서로 다른 시선: 멀티헤드 어텐션(Multi-head Attention)
하나의 문장 속에는 문법, 대명사의 지칭 대상, 감정, 논리적 인과관계 등 수많은 맥락이 얽혀 있습니다. 이를 단 하나의 어텐션으로 파악하기엔 역부족이죠. 그래서 트랜스포머는 여러 개의 어텐션이 동시에 작동하는 멀티헤드 어텐션 구조를 택했습니다.
GPT-3를 예로 들면, 무려 96개의 헤드가 존재합니다. 마치 96명의 전문 탐정이 각기 다른 단서를 쫓는 것과 같습니다. 어떤 탐정은 지시대명사 '그(He)'가 누구인지를 찾고, 다른 탐정은 문장의 감정이 긍정인지 부정인지를 분석하며, 또 다른 탐정은 시제의 일치 여부를 감시합니다.
이 탐정들이 제안하는 수정 방향을 모두 합쳐 원래 단어에 반영함으로써 모델의 지능이 완성됩니다. 실제로 GPT-3 전체 파라미터(1,750억 개) 중 약 1/3에 달하는 580억 개가 오직 이 어텐션 블록에 집중되어 있을 만큼, 그 비중과 중요성은 압도적입니다.
6. 결론: "Attention is All You Need"가 바꾼 세상
어텐션 메커니즘의 진정한 위력은 GPU를 통한 대규모 병렬 연산을 가능케 했다는 점에 있습니다. 덕분에 우리는 거대한 데이터를 쏟아부어 모델의 크기를 비약적으로 키울 수 있었고, AI는 인간의 언어를 놀라운 수준으로 이해하기 시작했습니다.
흥미로운 사실은, 기념비적인 논문의 제목은 어텐션이면 충분하다(Attention is All You Need)였지만, 실제 GPT-3의 파라미터 2/3는 지식을 저장하는 MLP(피드포워드) 블록에 할당되어 있다는 점입니다. 어텐션은 전부가 아니었을지라도(1/3), 전체 모델이 유기적으로 작동하게 만드는 '결정적 열쇠'였던 셈입니다.












'멀티모달' 카테고리의 다른 글
| LoRA: Low-Rank Adaptation (0) | 2026.04.06 |
|---|---|
| VAE(Variational Auto-Encoder) (0) | 2026.04.06 |
| Stable Diffusion (0) | 2026.04.06 |
| ComfyUI+n8n연동 (0) | 2026.04.05 |
| 'AI 광고' 표기에 등돌린 소비자들…마케팅 효과 '급감' (0) | 2026.03.12 |