인간의 눈으로 보기에 아주 살짝 옆으로 이동한(Shift) 이미지는 원본과 거의 똑같아 보입니다. 하지만 컴퓨터에게 단순한 픽셀 단위의 오차(MSE)를 계산하게 하면, 두 이미지는 완전히 다른 데이터로 인식됩니다. 반면 일부분이 잘려 나간 이미지는 컴퓨터 입장에서 오차가 적을 수 있지만, 인간에게는 명백히 손상된 데이터죠. 이 차이는 무엇을 의미할까요? 바로 인간은 데이터의 '표면'이 아닌 '본질적인 패턴'을 본다는 것입니다.
단순한 복사를 넘어 세상에 없는 고양이를 그려내고, 데이터의 숨은 의미를 포착하는 생성형 AI의 '상상력'. 그 중심에는 VAE(Variational Autoencoder)가 있습니다. VAE는 데이터를 단순히 압축하는 도구가 아니라, 데이터가 생성되는 확률적인 원리를 학습하여 AI가 스스로 새로운 가능성을 꿈꾸게 만드는 기술입니다.
--------------------------------------------------------------------------------
인코딩의 본질: 압축은 '가정'에서 시작된다
우리는 흔히 인코딩을 단순히 데이터 크기를 줄이는 기술로만 생각합니다. 하지만 기술적인 관점에서 인코딩은 데이터가 가진 패턴에 대한 **'가정'**이 전제될 때만 가능합니다.
0부터 9까지 10개의 버튼이 있는 상황을 떠올려 봅시다. 만약 어떤 버튼이든 동시에 여러 개가 눌릴 수 있다면, 우리는 10비트의 정보가 필요합니다. 하지만 '한 번에 단 하나의 버튼만 눌린다'는 규칙을 가정한다면 어떨까요? 이 10가지 경우의 수는 이진법을 통해 단 **4비트(0000~1001)**만으로도 충분히 표현할 수 있습니다.
"데이터가 실제로 갖는 경우의 수... 줄이는 가정이 있어야 인코딩을 할 수 있습니다."
이처럼 VAE는 고차원의 데이터(이미지 픽셀 등) 속에서 "이 데이터들은 특정한 패턴(가정)을 따르고 있을 것"이라는 전제를 바탕으로 핵심 정보만을 남기는 고도의 압축을 수행합니다.
--------------------------------------------------------------------------------
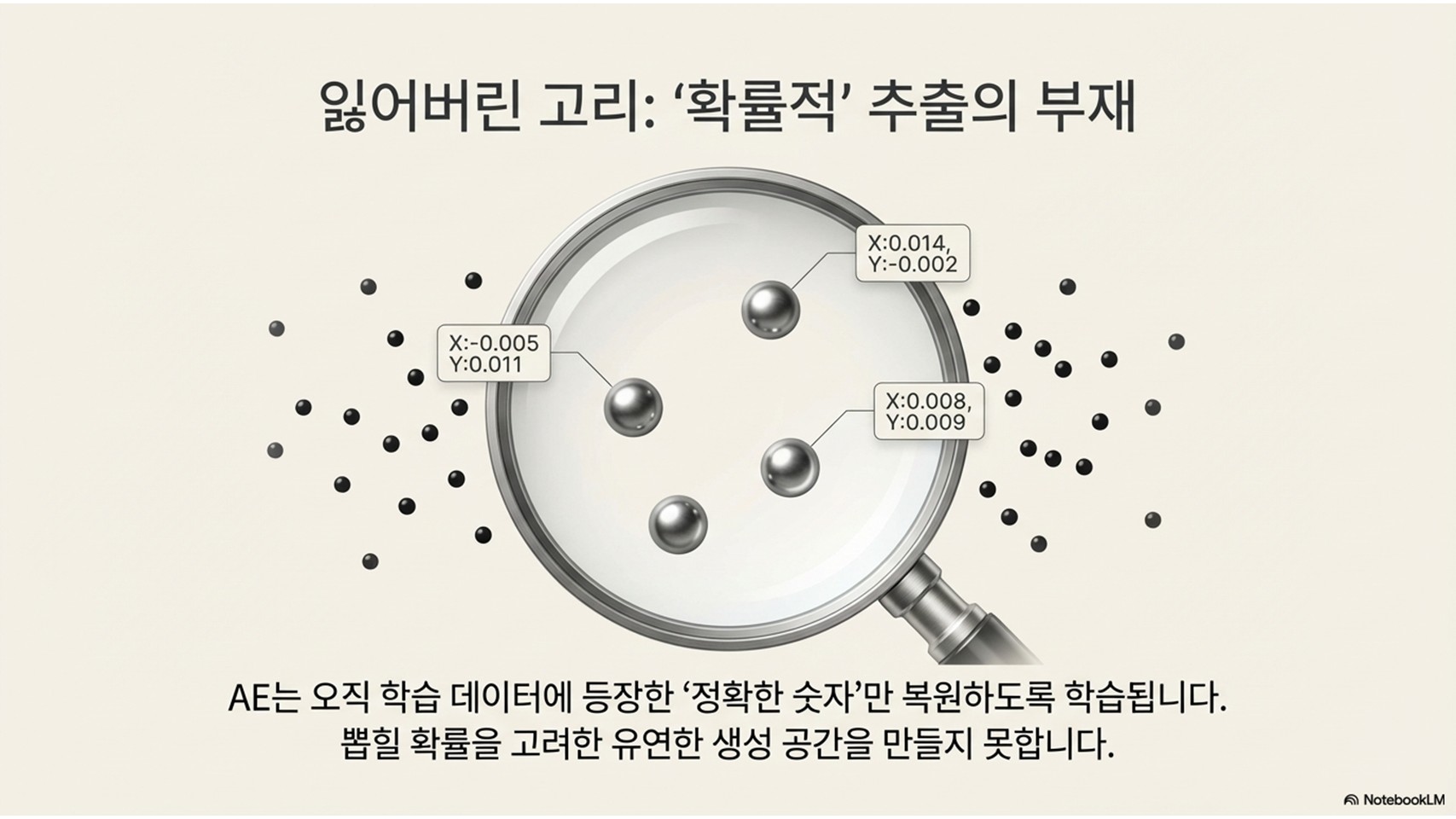
오토인코더(AE)는 왜 '훌륭한 생성 모델'이 될 수 없는가?
VAE의 모태가 된 **오토인코더(AE)**는 입력 데이터를 잠재 변수(Latent Variable)로 압축한 뒤 다시 원본으로 복원하는 구조를 가집니다. 하지만 결정적인 차이가 있습니다. 바로 **'결정론적(Deterministic)'**이냐, **'확률적(Probabilistic)'**이냐의 문제입니다.
일반적인 AE는 특정 입력 데이터를 잠재 공간의 특정 '지점(Point)'으로 기억합니다. 즉, 데이터의 특징을 고정된 상숫값으로 저장하는 일종의 '암기'에 가깝습니다. 이 방식은 특징 추출에는 유리하지만, 새로운 데이터를 생성하기 위해 학습하지 않은 지점에서 값을 뽑으면(샘플링) 정체를 알 수 없는 노이즈가 출력됩니다. 잠재 공간 곳곳에 데이터가 채워지지 않은 '빈 공간'이 존재하기 때문입니다. 반면 VAE는 데이터를 하나의 지점이 아닌 '확률 분포'로 학습하여 이 공간을 촘촘하게 메웁니다.
--------------------------------------------------------------------------------
'계산 불가능'에 도전하는 수학적 기교, ELBO
생성 모델의 핵심은 학습 데이터의 분포인 **Marginal Likelihood(p(x))**를 최대화하는 것입니다. 하지만 수천 차원의 이미지 데이터와 복잡한 신경망 구조에서 이 값을 직접 적분하여 구하는 것은 수학적으로 **계산 불가능(Intractable)**한 영역입니다.
이를 해결하기 위해 VAE는 **'변분 추론(Variational Inference)'**이라는 전략을 사용합니다. 우리가 알 수 없는 실제 분포(p(z|x))를, 다룰 수 있는 단순한 분포(가우시안 분포 등)로 근사시키는 것입니다. 이때 목표를 달성하기 위해 끌어올리는 하한선이 바로 **ELBO(Evidence Lower Bound)**입니다.
수학적으로 Likelihood = ELBO + KL Divergence의 관계가 성립합니다. 여기서 두 분포의 차이를 나타내는 KL Divergence는 항상 0보다 크거나 같기 때문에, 우리가 계산할 수 있는 ELBO를 최대화하면 자연스럽게 목표인 Likelihood에 접근하게 됩니다. 복잡한 적분을 직접 계산하는 대신, 영리하게 '최소 하한선'을 밀어 올리는 전략을 취하는 것입니다.
--------------------------------------------------------------------------------
노이즈의 역설: 방해 요소가 '창의성'의 근원이 되다
VAE가 일반적인 AE와 차별화되는 지점은 인코딩 과정에 의도적으로 '베리에이션(Variation)', 즉 노이즈를 섞는다는 점입니다. 이는 단순히 한 점을 복원하는 학습을 넘어, 그 지점의 **주변 영역(Neighborhood)**까지 한꺼번에 학습하게 만드는 기술입니다.
"인코딩 숫자에 대해서만 복원하는 게 아니라... 근처의 숫자들에 대해서도 복원했을 때 자기 자신이 나오도록 학습합니다."
VAE의 손실 함수는 두 가지 핵심 요소로 구성됩니다.
- Reconstruction Term (복원 항): 입력 데이터를 얼마나 정확하게 재구성하는가?
- Regularization Term (규제 항): 인코딩된 분포가 우리가 설정한 사전 분포(Prior, 주로 표준 정규 분포)와 얼마나 유사한가?
노이즈를 섞는 '규제' 과정 덕분에 잠재 공간은 특정 데이터들로만 파편화되지 않고 연속적인 공간으로 변모합니다. 이 연속성이 확보될 때, 비로소 AI는 학습 데이터 사이의 빈틈을 메우며 자연스럽고 새로운 이미지를 만들어낼 수 있는 '유연성'을 얻게 됩니다.
--------------------------------------------------------------------------------
재파라미터화(Reparameterization): 미분 불가능한 '운명'을 바꾸는 속임수
VAE 학습에는 치명적인 기술적 난관이 있습니다. 바로 '샘플링'입니다. 확률 분포에서 값을 무작위로 뽑는 과정은 수학적으로 미분이 불가능합니다. 딥러닝의 엔진인 역전파(Backpropagation)가 이 지점에서 끊겨버려 모델 전체를 학습시킬 수 없게 됩니다.
VAE는 이를 **'재파라미터화 트릭(Reparameterization Trick)'**이라는 영리한 수법으로 해결합니다. 랜덤한 요소(\epsilon)를 모델 외부에서 유입되는 상숫값으로 분리해버리는 것입니다.
구체적으로는 z = \mu + \sigma \odot \epsilon 공식을 사용합니다. 학습해야 할 파라미터인 평균(\mu)과 표준편차(\sigma)는 네트워크 안에 남겨두어 미분 가능한 경로를 확보하고, 무작위성(\epsilon)만 밖으로 빼내는 방식입니다. 이 트릭 덕분에 랜덤한 샘플링 과정을 포함하면서도 전체 네트워크가 안정적으로 학습될 수 있는 길이 열렸습니다.













'멀티모달' 카테고리의 다른 글
| Denoising Diffusion Probabilistic Models (0) | 2026.04.07 |
|---|---|
| LoRA: Low-Rank Adaptation (0) | 2026.04.06 |
| Attention (0) | 2026.04.06 |
| Stable Diffusion (0) | 2026.04.06 |
| ComfyUI+n8n연동 (0) | 2026.04.05 |