TF-IDF 토큰화 → Vector화 → Embedding
비정형 데이터(Text)를 수치형 벡터로 변환하여 기계가 이해할 수 있는 좌표계로 옮기는 작업
1. 토큰화
tfidf_vectorizer.fit_transform(texts) 함수가 호출될 때 내부적으로 자동 수행됩니다.
- 방식: 기본 설정은 공백(Space) 기준이며, 2글자 이상의 단어를 토큰으로 간주합니다.
- 한계: 한국어는 조사(이, 가, 을, 를)가 단어 뒤에 붙는 '어절' 구조라 공백으로만 나누면 코어위브에, 코어위브로부터를 서로 다른 단어로 인식하는 단점이 있습니다.
- 확인: tfidf_vectorizer.get_feature_names_out()을 출력했을 때 나오는 단어 목록들이 바로 토큰화된 결과물입니다.
openai.embeddings.create(...) 함수를 통해 문장을 보낼 때 OpenAI의 서버 안에서 수행됩니다.
- 방식: OpenAI는 tiktoken이라는 라이브러리의 Byte Pair Encoding(BPE) 방식을 사용합니다.
- 특징: 단어를 더 작은 단위(Subword)로 쪼개기 때문에 '코어위브에' 같은 단어도 '코어위브'와 '에'의 의미를 어느 정도 분리해서 이해할 수 있습니다. 사용자는 직접 토큰화 코드를 작성할 필요 없이 문장 전체를 API에 전달만 하면 됩니다.
2. TF-IDF 벡터화
이 부분은 단어의 빈도수를 계산하여 텍스트를 숫자로 변환합니다.
- TfidfVectorizer(): "어떤 단어가 이 문서에서 얼마나 중요한가?"를 계산하는 도구입니다. 흔한 단어(은, 는, 이, 가)의 가중치는 낮추고, 핵심 단어(엔비디아, 국채, 핵클럽)의 가중치는 높입니다.
- fit_transform(texts): 문장들을 분석해 단어 사전(Vocalbulary)을 만들고, 각 문장을 해당 단어들의 점수로 이루어진 행렬(Matrix)로 변환합니다.
3. OpenAI Embedding
단순 빈도 계산을 넘어, 단어의 '의미'와 '맥락'을 파악하여 고차원 공간상의 좌표로 변환합니다.
- get_embedding(text): OpenAI의 text-embedding-3-large 모델을 사용합니다. 이 모델은 문장을 3,072차원의 숫자 리스트로 변환합니다.
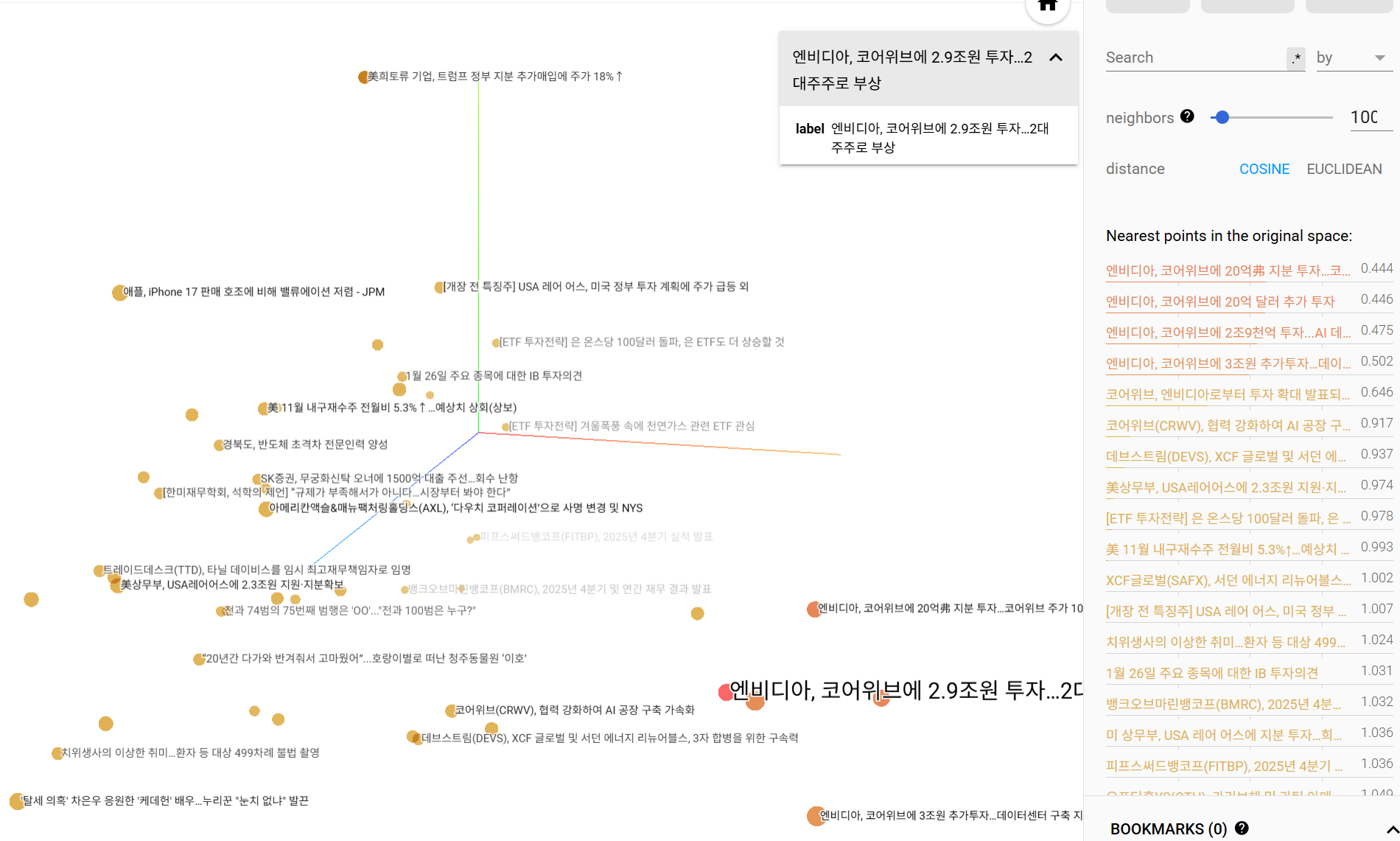
- 예: "상승"과 "오름세"는 글자는 다르지만, 임베딩 공간에서는 매우 가까운 위치에 배치됩니다.
texts = ['美 국채가, 동반 강세…차기 연준 의장 향배에 경계감',
'트레이드데스크(TTD), 타닐 데이비스를 임시 최고재무책임자로 임명',
'러 前대통령, 뉴스타트 만료 앞두고 "핵클럽 확장될 것"',
'\'탈세 의혹\' 차은우 응원한 \'케데헌\' 배우…누리꾼 "눈치 없냐" 발끈',
'엔비디아, 코어위브에 2.9조원 투자…2대주주로 부상',
'[한미재무학회, 석학의 제언] “규제가 부족해서가 아니다…시장부터 봐야 한다”',
'SK증권, 무궁화신탁 오너에 1500억 대출 주선…회수 난항',
'아메리칸액슬&매뉴팩처링홀딩스(AXL), ‘다우치 코퍼레이션’으로 사명 변경 및 NYS',
'전과 74범의 75번째 범행은 \'OO\'..."전과 100범은 누구?"',
"트럼프, 연방요원 총격에 2명 숨진 미네소타에 '국경차르' 파견",
'뉴욕증시 개장 전 특징주...뉴몬트·앱러빈·아이온큐↑ VS 엔페이즈·항공주↓',
'“7살 연상 아내가 애 취급, 부부관계도 늘 명령조…이런 걸로도 이혼 되나요”',
'美상무부, USA레어어스에 2.3조원 지원·지분확보',
'대구시, 설 명절 앞두고 ‘건설 현장’ 특별안전점검',
'코어위브(CRWV), 협력 강화하여 AI 공장 구축 가속화',
'크리네틱스파마슈티컬스(CRNX), 임원 변경 및 직책 조정 발표',
'경북도, 반도체 초격차 전문인력 양성',
'엔비디아, 코어위브에 3조원 추가투자…데이터센터 구축 지원',
'타리뮨(THAR), 칸톤 네트워크에서 슈퍼 밸리데이터로 역할 확대 발표',
'트로스파르마(TRAW), COVID-19 환자 대상 Ratutrelvir 임상 연구 등록 완료 및 Tivo',
'"한국인만 먹었다고?"…美에서 난리난 \'마약 달걀\' 레시피',
'시티즌스커뮤니티뱅코프(CZWI), 2025년 4분기 실적 발표',
"미 상무부, USA 레어 어스에 지분 투자…희토류 공급망 '탈중국' 가속",
'美 11월 내구재수주 전월비 5.3%↑…예상치 상회(상보)',
'벨로시티파이낸셜(VEL), 2025년 4분기 및 연간 실적 발표',
'오프더훅YS(OTH), 카리브해 및 라틴 아메리카로의 확장 발표',
'엔비디아, 코어위브에 20억 달러 추가 투자',
'피프스써드뱅코프(FITBP), 2025년 4분기 실적 발표',
'美희토류 기업, 트럼프 정부 지분 추가매입에 주가 18%↑',
'강원랜드 임직원 한파 속 연탄 나눔 봉사..석탄산업전환지역의 연탄이 되다',
'데브스트림(DEVS), XCF 글로벌 및 서던 에너지 리뉴어블스, 3자 합병을 위한 구속력',
'비트마인이머전테크놀로지스(BMNR), ETH 보유량 424만 3천 개 토큰 도달 및 총 암호',
'뱅크오브마린뱅코프(BMRC), 2025년 4분기 및 연간 재무 결과 발표',
'‘쇼미12’글로벌 래퍼·해외파 래러·국내 래퍼 섞여 다양한 랩 나온다…트레이비·정준혁 같은 래퍼 찾는다',
'“20년간 다가와 반겨줘서 고마웠어”...호랑이별로 떠난 청주동물원 ‘이호’',
'치위생사의 이상한 취미…환자 등 대상 499차례 불법 촬영',
'XCF글로벌(SAFX), 서던 에너지 리뉴어블스 및 데브스트림, 3자 합병을 위한 구속력',
"EU, 머스크 AI 그록 '딥페이크 생성' 조사",
'엔비디아, 코어위브에 2조9천억 투자...AI 데이터센터 동맹 확대',
'코어위브, 엔비디아로부터 투자 확대 발표되며 상승',
'1월 26일 주요 종목에 대한 IB 투자의견',
'美희토류 기업, 트럼프 정부 지분 추가매입에 주가 18%↑',
'[ETF 투자전략] 은 온스당 100달러 돌파, 은 ETF도 더 상승할 것',
'[ETF 투자전략] 일본 ETF, 경제성장률 전망치 상향되면서 관심',
'[ETF 투자전략] 겨울폭풍 속에 천연가스 관련 ETF 관심',
'엔비디아, 코어위브에 20억弗 지분 투자…코어위브 주가 10% 급등',
'메타, 수익화 능력에 비해 저평가된 상태 로스차일드',
'[개장 전 특징주] USA 레어 어스, 미국 정부 투자 계획에 주가 급등 외',
'애플, iPhone 17 판매 호조에 비해 밸류에이션 저렴 - JPM']
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
import openai
import time
import csv
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(texts)
print(tfidf_matrix.toarray())
print(tfidf_vectorizer.get_feature_names_out())
df = pd.DataFrame(tfidf_matrix.toarray(), columns=tfidf_vectorizer.get_feature_names_out())
print(df)
def get_embedding(text, model="text-embedding-3-large"):
response = openai.embeddings.create(
input=text,
model=model
)
return response.data[0].embedding
embeddings = []
metadata = []
for idx, text in enumerate(texts):
print(f"Embedding {idx+1}/{len(texts)}: {text}")
try:
emb = get_embedding(text)
embeddings.append(emb)
metadata.append(text)
time.sleep(0.1) # API rate limit 회피용
except Exception as e:
print(f"Error embedding '{text}':", e)
with open("embeddings.tsv", "w", newline="",encoding="utf-8") as f:
writer = csv.writer(f, delimiter="\t")
for emb in embeddings:
writer.writerow(emb)
with open("metadata.tsv", "w", newline="",encoding="utf-8") as f:
for text in metadata:
f.write(text + "\n")
https://projector.tensorflow.org/
'LLM' 카테고리의 다른 글
| 보안과 실무 효율을 동시에 잡는 SLM 도입 및 활용 전략 (0) | 2026.03.22 |
|---|---|
| LLM의 학습 데이터 (0) | 2026.01.27 |
| Tokenization, Vectorization and Embedding (0) | 2026.01.26 |
| LLM 만들기 Fine tuning (0) | 2026.01.25 |
| LLM 만들기 Pretraining (0) | 2026.01.25 |